If you’ve ever trained a GNN or Graph Transformer on Cora or PubMed, you probably walked away thinking: “This isn’t so different from any other PyTorch model.” You define a couple of message-passing layers, run your training loop, and everything works. Then you try the same thing on your company’s real data: tens of billions of nodes, dozens of edge types, terabytes of features, and edges timestamped down to the millisecond. Suddenly, your GPU isn’t the bottleneck anymore. Your jobs are stuck on data prep, your disk fills up with neighborhood dumps, and your offline metrics look suspiciously better than production. This post is about that moment. It’s a step-by-step guide to what actually changes when you move from toy GNNs to large-scale, production training—and how Kumo’s training backend addresses the bottlenecks that appear along the way.Documentation Index
Fetch the complete documentation index at: https://kumo.ai/docs/llms.txt
Use this file to discover all available pages before exploring further.
1. The Hidden Complexity of Graph Learning
When you train on images, each example is a tensor of pixels. With tabular data, it’s a vector of features. These are fixed, self-contained inputs. GNNs are different. Every example depends on a neighborhood—a dynamically constructed subgraph around the node or edge you care about. For example:- For a recommender, the neighborhood of a user might include the items they clicked, the other users who clicked those same items, and the items those users clicked in turn.
- For fraud detection, the neighborhood of a bank account might include all the transactions it participated in, the counterparties to those transactions, and the other accounts those counterparties interacted with.
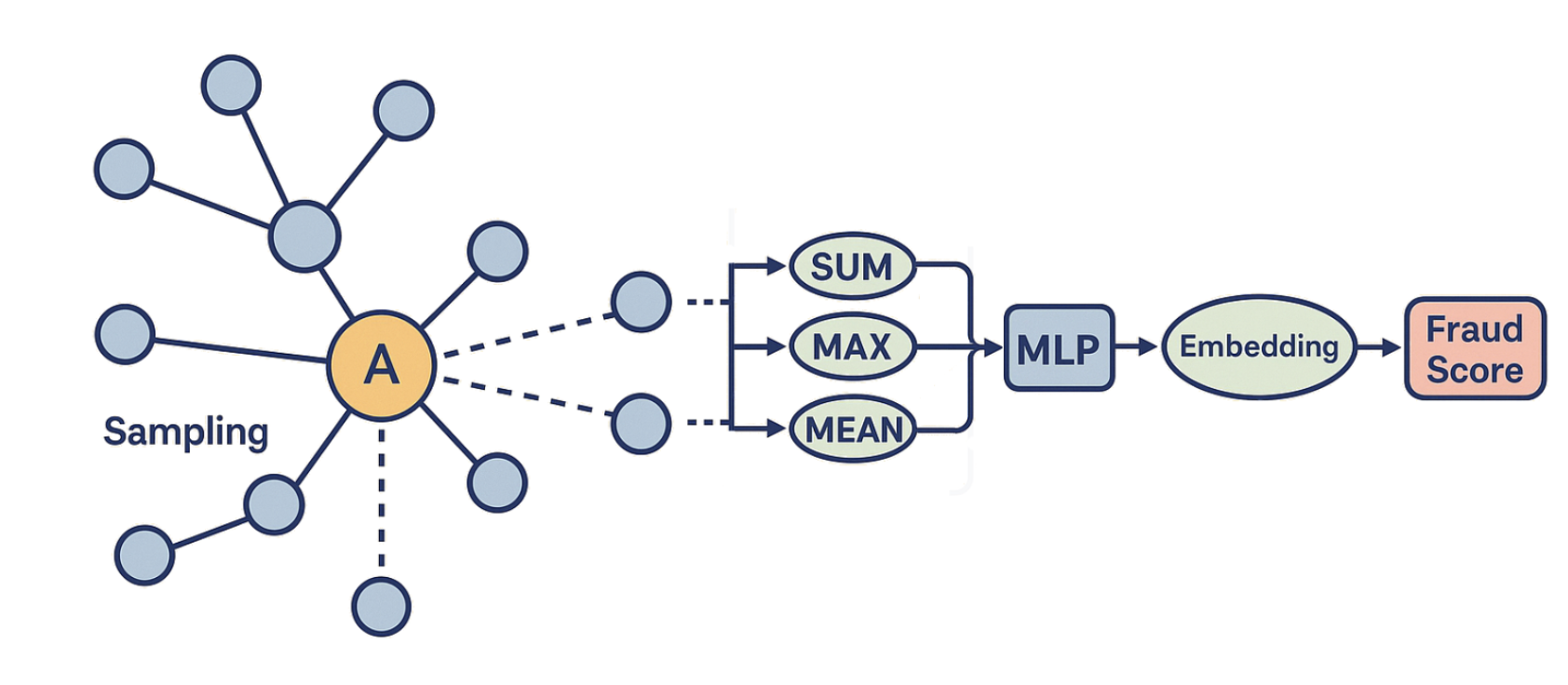
2. The First Attempt: Precomputing Neighborhoods with Spark
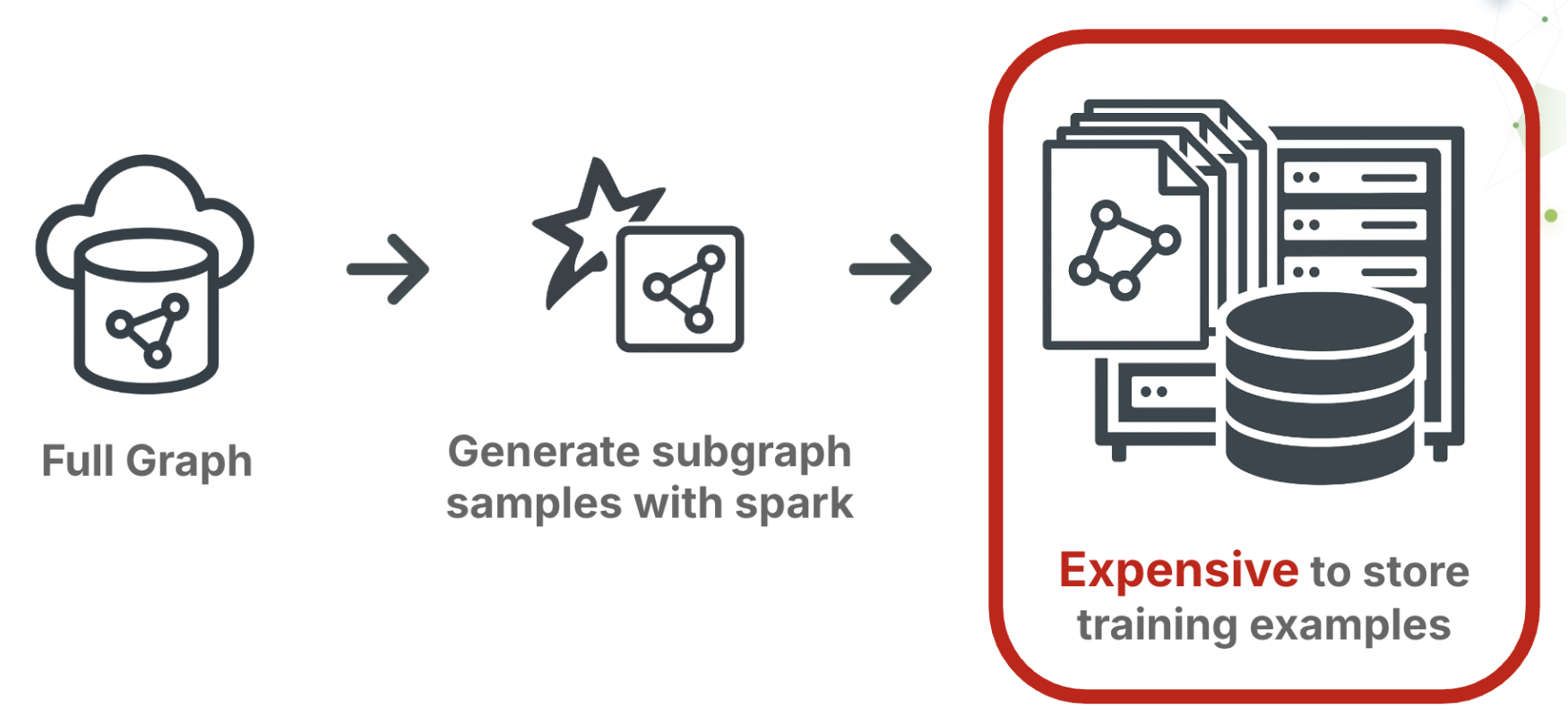
Most teams start where they’re comfortable: Spark or SQL. You can write recursive joins that traverse the graph for 2–3 hops, attach features, and write out the subgraphs as training data. This works on small datasets. But production graphs expose its weaknesses quickly:- Data blow-up. A single 3-hop neighborhood can be hundreds of MB. Materialize millions of them and you’ve got terabytes of intermediate data.
- Iteration is painful. Change your fanout or hop depth? Back to Spark for a full re-run.
- Neighborhoods go stale. Real graphs evolve constantly; static dumps don’t.
- Temporal leakage sneaks in. Unless you’re meticulous about time filtering, you’ll end up training on “future” edges, which inflates validation metrics but fails in production.
3. The Shift: Online Sampling
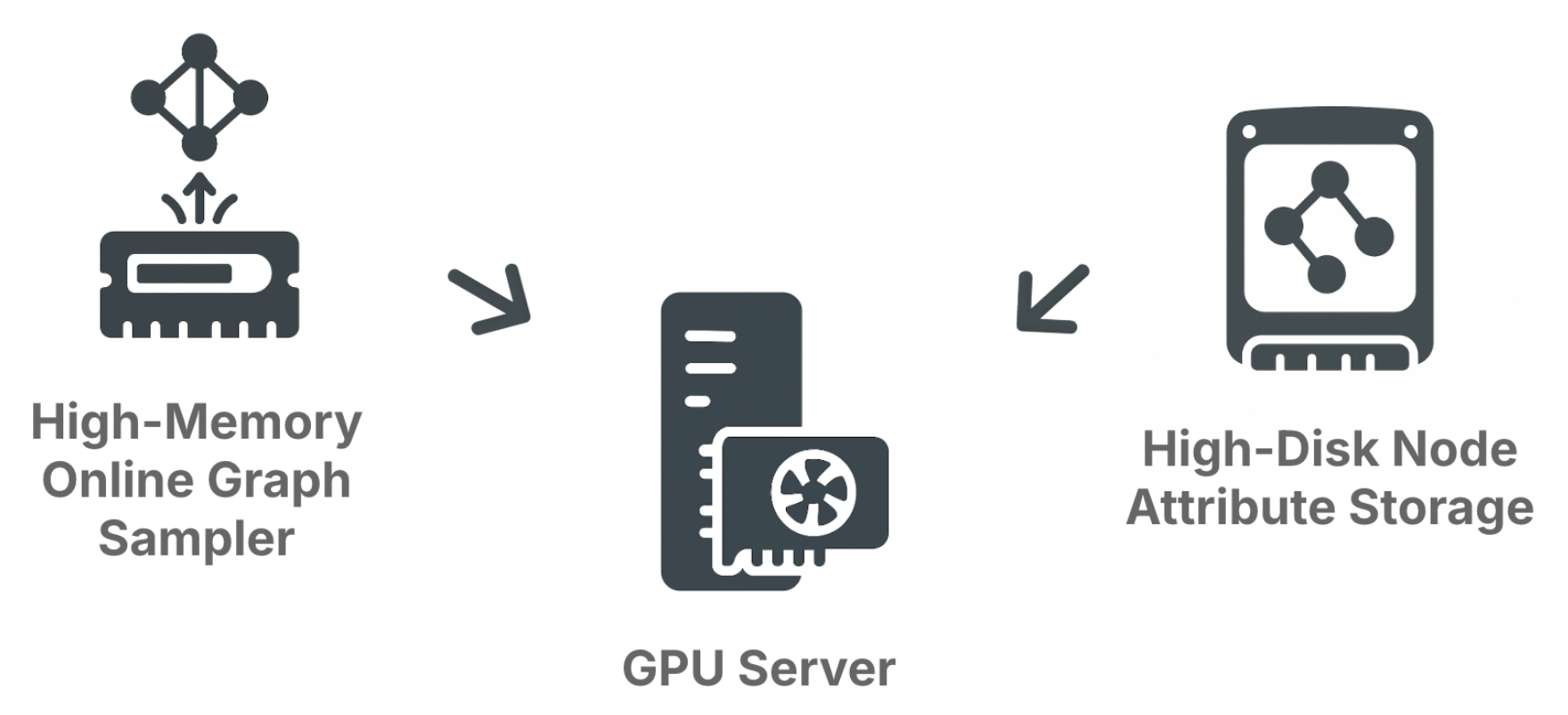
The way forward is to stop precomputing and start sampling neighborhoods online. Instead of treating neighborhoods as static data, you treat them as queries: each batch asks for a fresh neighborhood, sampled just in time. This pattern emerged independently at large companies like Pinterest (PinSage) and Alibaba (AliGraph). At Kumo, we’ve built a backend that packages the same approach into something engineers and data scientists can use directly. Here’s how it works:- Graph Sampler (RAM): The sampler holds the graph structure in memory for ultra-fast lookups. It expands neighborhoods according to your configuration: hop depth, fanouts per edge type, metapaths, and time constraints. Temporal correctness is enforced automatically—you only ever see edges valid at the time of the training example.
- Feature Store (SSD): The sampler returns node IDs. The feature store fetches their attributes from SSD storage. This allows you to work with terabytes of features without overloading GPU memory.
- GPU Trainer (PyTorch): Once you have the subgraph and its features, the rest looks familiar. You run it through your GNN or transformer layers, compute a loss, and backpropagate.
4. What This Architecture Enables
By shifting to online sampling, you unlock scale that was previously infeasible. For example:| Parameter | Example Capability |
|---|---|
| Graph Size | 10–30 Billion nodes (1TB server) |
| Subgraph Depth | 6+ hops (on sparse graphs) |
| Inference | Batch or Online (inductive) |
| Sampling | Static or Temporal (per metapath) |
5. Relating Back to PyTorch
If you’re already comfortable with PyTorch, the analogy is straightforward.- The graph sampler is like a
DataLoader. Instead of rows, it emits subgraphs. - The feature store is like a
collate_fn, attaching attributes to nodes and edges in the batch. - The model is still an
nn.Module. Whether you use GraphSAGE, GAT, or a transformer, it plugs in here.
6. Working with Real Graphs
Toy benchmarks usually show simple, homogeneous graphs. Real production graphs look very different: multiple node types, multiple edge types, and timestamped interactions. Training at scale means controlling how neighborhoods are sampled, not just how many layers your model has. In Kumo, this is exposed through thenum_neighbors parameter. This setting tells the sampler how many neighbors to expand at each hop. For example, you might configure:
num_neighbors give you the knobs you need.
7. Putting It Into Practice
Here’s what working with Kumo looks like end to end:- Define your task. Use a Predictive Query to specify the entity you’re predicting for (e.g. user churn, fraud risk).
- Generate a ModelPlan. The SDK can suggest one (
pquery.suggest_model_plan()), which you can then customize. See the SDK trainer reference. - Configure sampling. Neighborhood expansion is controlled through
num_neighbors, with per-hop and per-edge fanouts. - Train your model. Launch training with the Trainer API. Batches are generated online, so GPUs always see fresh neighborhoods.
- Run inference. Use the same sampler settings for batch prediction or online scoring, ensuring consistency between training and serving.
8. Takeaways
Training GNNs at scale teaches a simple lesson: the bottleneck isn’t the math, it’s the neighborhoods.- Precomputing with Spark doesn’t scale.
- Online sampling is the architecture that works in practice.
- With the right backend, billion-node graphs are trainable, and GNN training feels approachable again.